Intelligent Assistance for Expert-Driven Subpopulation Discovery in High-Dimensional Timestamped Medical Data
My PhD thesis.
PhD Thesis, University of Magdeburg
By Uli Niemann in Research
June 17, 2021
Abstract
Subpopulation discovery is an essential objective of data analysis in medical research and contributes to the prevention and treatment of adverse medical conditions. Characteristic subpopulations are detected, for example, by identifying long-term determinants of diseases or by revealing patient subgroups with differential responses to treatment.
Traditional medical data analysis has been mostly hypothesis-driven. With the increasing volume and heterogeneity of medical data, these workflows are becoming impractical, as important relationships between variables may go undetected. Besides, medical studies often involve measurements that are collected repeatedly over time. Investigating hidden temporal information can potentially lead to new insights. While machine learning has the potential of automatically detecting previously unknown subpopulations, the results of complex black-box models must be made understandable. Therefore, the medical expert must be equipped with tools to understand, explore, and visualize the models, breaking down individual patterns to extract actionable insights.
This thesis proposes machine learning-based solutions for expert-driven subpopulation discovery in high-dimensional timestamped medical data.
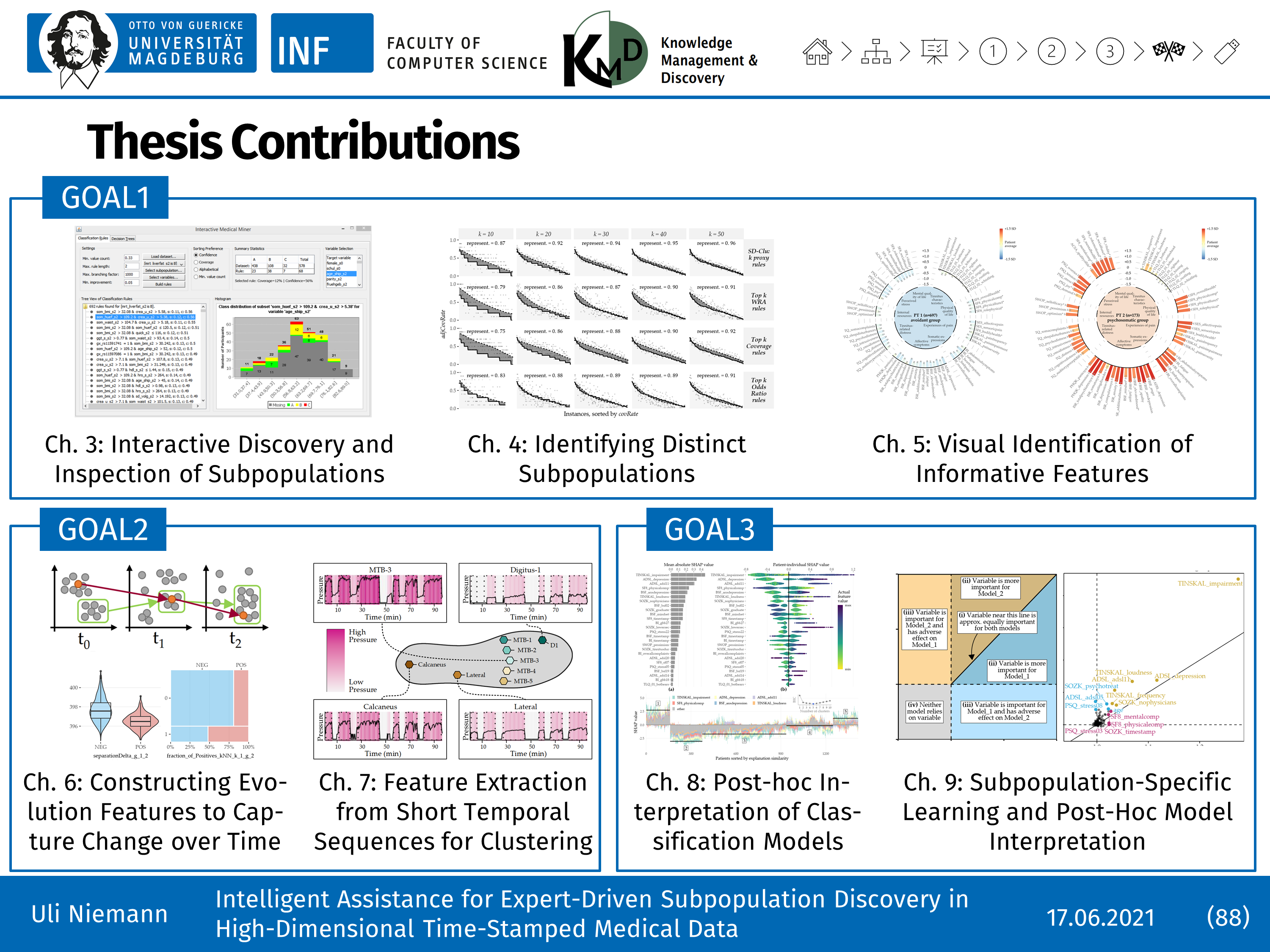
The first part presents workflows to detect comprehensible and distinct subpopulations described by classification rules and clusters. We present novel visualizations and interactive tools to inspect and juxtapose the high-dimensional subpopulations and compare their change over time.
The second part covers workflows to exploit temporal information. We present a framework to extract evolution features that characterize the subpopulations' change over time. Furthermore, we provide a method to build representations from short temporal sequences.
The third part addresses the topic of post-hoc interpretation of complex black-box models. We propose an end-to-end data analysis workflow that includes steps for data augmentation, modeling, nesting model training with feature elimination, and post-hoc analysis of the trained models. This workflow returns statistics and visualizations representing global feature importance, instance-individual feature importance, and subpopulation-specific feature importance for a machine learning model of any type. Besides, we provide a solution for visualizing differences between two a priori defined subpopulations.
The proposed methods are evaluated with datasets from four medical studies:
- a longitudinal population study,
- an observational therapy study with data on self-report questionnaire responses from tinnitus patients,
- a clinical experiment with timestamped plantar pressure and temperature recordings from diabetes patients and healthy volunteers, and
- a retrospective clinical study with image data on intracranial aneurysms.
Important figure
BibTeX citation
@PhdThesis{Niemann:PhD-Thesis2021,
author = {Niemann, Uli},
school = {Otto von Guericke University Magdeburg},
title = {{Intelligent Assistance for Expert-Driven Subpopulation Discovery in
High-Dimensional Timestamped Medical Data}},
year = {2021},
doi = {10.25673/37453},
url = {https://opendata.uni-halle.de//handle/1981185920/37696},
}